
I’ve been working with the same engineering team for about a year and a half now, and one problem that keeps rearing up that we struggle to solve long-term is one of a lack of focus. We have ~4 distinct “products” that we own, and 5 engineers on the team, so it’s not uncommon for us to end up with each person supporting a different product. The challenge with this model is that we end up with not making much progress on any individual product, and the engineers are constantly context-switching. Plus, they end up feeling pretty siloed, which frequently comes up in our retros.
We know this is a problem, and the solution seems simple: do fewer things. Simple, yes. Easy, no.
When something new comes in – a customer problem, a discovered bug, a feature ask from leadership – it’s hard to say no. Every ask is reasonable. Some people it’s hard to know if we’re even allowed to tell them no. So everything is a yes, everything’s on the backlog, no we can’t provide a time estimate but we’ll get to it eventually. My backlog is full of “that’s a great idea but we don’t have the bandwidth”s and “we should really get to this or it’ll bite us”s. My 2021 roadmap is a wasteland of half-finished projects and changing priorities. I looked back on this in December and asked, how can we make 2022 better? How can we craft practices now that will end up with us looking at 2022 and seeing things that are connected, make sense, and get finished?
Here’s what I’m trying:
- Clarify the team’s vision & mission
- Create metrics that tie to our vision so we can visualize progress better
- Create principles about the work we do & don’t do that tie to the metrics
- Craft a focused operational cadence so that we can continually ensure we are adhering to our principles
Again, fairly simple, not so easy. Here’s what I have so far.
Clarify the Team’s Vision & Mission
In a workshop, as a team, we discussed what’s most important to us, and how we think we can have the biggest impact in the org. Crucially, this is not about what features or work we can do – this is at a higher level, exploring why we exist as a team. After going through a number of brainstorming exercises, we landed on: “We aim to accelerate service development for the rest of Engineering. We achieve this by reducing friction of working with services, building a reliable platform using best practices, and scaling our support for teams.”
Create metrics that tie to our vision so we can visualize progress better
Here, I did a pseudo-north-star framework. It looks like this:
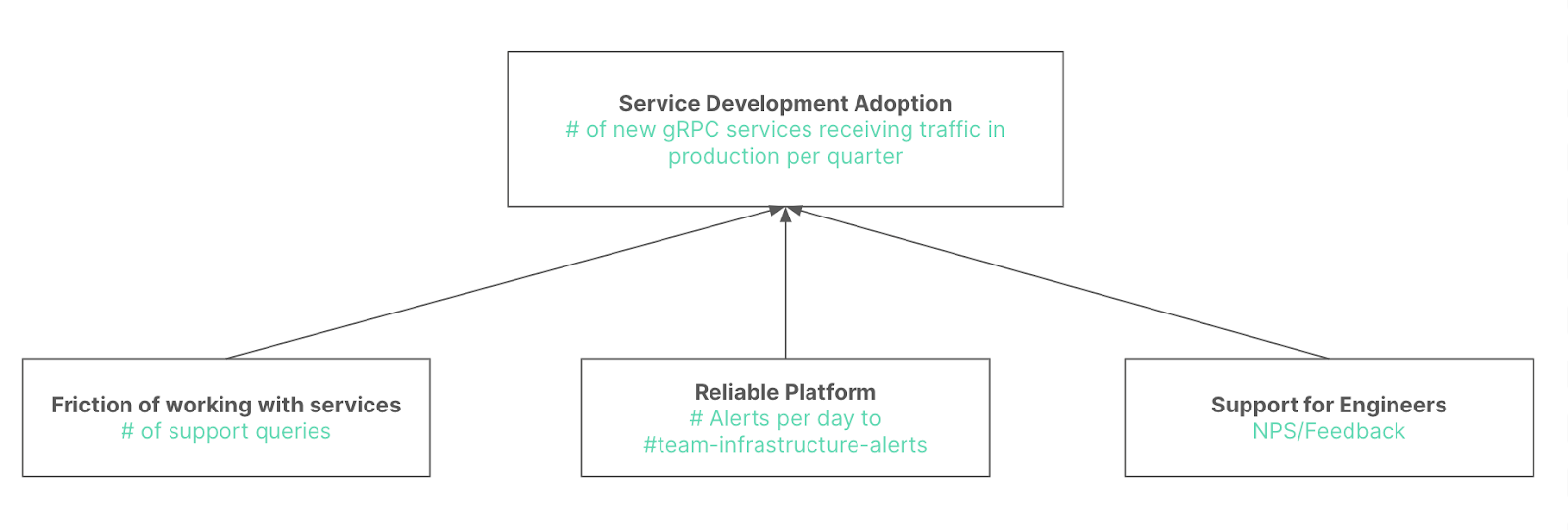
Our “north star” (I use quotes and call it a pseudo-north star because I think, technically, North Stars are not really meant for individual teams and are more intended to be used at the org level) is service development adoption, as measured by new services receiving traffic in production each quarter. The three inputs tie to the 3 things we think we can do to push that forward: reducing friction (as measured by # of support queries we receive over a TBD length of time), making a reliable platform (as measured by alerts we receive daily), and supporting engineers (as measured by some sort of NPS or feedback score). As you can see, these metrics still need some refinement, but we’re moving in the right direction. Simply by creating these categories for the type of work we do, we were already able to strike a number of things from our backlog. Progress!
Create principles about the work we do
This one is definitely a work in progress. Some principles we came up with in a workshop are:
- Documentation = Development: As a deliverable, documentation published is equal to code shipped. Every piece of work has accompanying documentation, and efforts to improve documentation are prioritized alongside features.
- Scaling helpfulness > Quick answers: As the organization grows and our system becomes more complex, we are finding requests for our support are increasing. By documenting frequent questions or creating tutorials, we would prefer to teach our customers to self-serve answers than always being available to answer synchronously.
- Preventing engineers from being blocked > Unblocking engineers: We would like to be proactive whenever possible. By understanding our customers better, we can build out the features they need before they need them, and prevent them from becoming blocked on our technology.
What I like about these is that it helps guide some of our behaviour – for example, the first one means that we try to incorporate documentation into every piece of work, instead of treating it separately. What I don’t like about these at the moment is that it does not give us a framework to prioritize/filter requests for work that we do. Where I’d like to end up with these is almost a flowchart that can help us decide what work to do or not to do.
Craft a focused operational cadence
This is maybe the hardest part. Changing the way you work when you’ve been doing the same thing for a while is tough. It’s easy to fall into the trap of thinking you can just change all the things at once, but like anything in life, sustainable change is slow change. So, there are 2 small changes we’re implementing in the short term:
- An experiment where, for 1 month, every engineer is working on the same project. This was a tough one to get the team to agree to! Only by framing it as a short-term experiment could I get everyone on board (including myself! There’s so much to do and it all FEELS important). I’m hopeful this will help us make better progress and feel less siloed.
- Embracing Kanban and WIP limits. We’ve been working in a pseudo-Scrum way for a while now – tracking and planning sprints in Jira, but not really adhering to them strongly. So, we’re doing away with sprint buckets, and I’ll be looking to implement limits for how many tickets can be in progress at once. The intention of this in Kanban is to optimize flow of work and reduce the impact of bottlenecks.
In the medium-to-long term, in combination with “creating principles about the work we do/don’t do”, I’m hoping to create a system by which the team regularly reviews, filters, and prioritizes incoming work. We have a prioritization system right now, but not a filtering system, so our backlog is giant and messy.
An interesting twist to all this is that, with my role change (as described in “P* Management”), I have to do all this with an eye towards not being the one to run the operations for the team in an ongoing way. I have to build these processes so that the team can run them without me, because I’ll be moving my focus to larger parts of the org in time and won’t be paired with a single team for the long term any more.
There’s a bunch of work ahead of me to refine this and set the team up for success, but I’m feeling good about what we’ve accomplished so far and optimistic about the prospects for the year.